The concept of a data lakehouse is gaining serious traction, and for good reason! It combines the flexibility and cost-effectiveness of a data lake with the data management features and ACID transactions of a data warehouse. Let’s dive into building a practical lakehouse setup using some fantastic open-source and cloud-native tools: DuckDB with its DuckLake extension, Google Cloud Storage (GCS) for our data storage, and Neon for a serverless PostgreSQL metadata store.
This setup allows you to keep your raw data in affordable cloud storage while leveraging DuckDB’s powerful analytical capabilities locally and PostgreSQL for robust metadata management.
Why this Stack?
- DuckDB: An in-process analytical data management system. It’s incredibly fast, easy to use, and has a growing ecosystem of extensions. The DuckLake extension will be key for interacting with our cloud storage. Find the installation instructions here.
- Google Cloud Storage (GCS): A scalable, secure, and durable object storage service. Perfect for storing large volumes of data. Create a bucket where you’ll store your data lake files. While we’re using GCS, services like AWS S3 or Azure Blob Storage are also compatible.
- Neon PostgreSQL: A serverless, fully managed PostgreSQL service. It offers a free tier and is ideal for our metadata backend without the hassle of managing a database server. Sign up at Neon and create a new project. Any other PostgreSQL or MySQL instance would work as well.
- Two SQL Engines, Best of Both Worlds: We’ll use DuckDB for local data processing and querying directly on files in cloud storage, and PostgreSQL as the central catalog holding information about our datasets.
Setting Up DuckDB with Extensions 🦆
First, let’s fire up DuckDB:
> duckdb
duckdb
DuckDB v1.3.0 (Ossivalis) 71c5c07cdd
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D
Now, install the necessary extensions. We’ll need httpfs to allow DuckDB to read from and write to GCS, postgres to connect to our Neon metadata database, and of course, ducklake to tie it all together.
INSTALL httpfs;
INSTALL postgres;
INSTALL ducklake;
Configuring Secrets
To securely connect to GCS and PostgreSQL, DuckDB allows you to create secrets.
For Google Cloud Storage you’ll need to create a Hash-based Message Authentication Code (HMAC) key. See DuckDB documentation for details:
CREATE SECRET (
TYPE gcs,
KEY_ID 'your_key_id',
SECRET 'your_secret'
);
For Neon PostgreSQL you’ll get a connection string from your Neon dashboard. Use the components of the connection string to declare the secret. See DuckDB documentation for details:
CREATE SECRET (
TYPE postgres,
HOST 'your_hostname',
DATABASE 'your_database',
USER 'yout_user',
PASSWORD 'your_password');
To make the secrets persistent between DuckDB runs, use CREATE PERSISTENT SECRET.
Create the Data Lakehouse 🌊
Now, let’s create our lakehouse using the PostgreSQL instance and our Google Cloud Storage bucket:
ATTACH 'ducklake:postgres:' AS lakehouse (DATA_PATH 'gs://your_bucket/');
USE lakehouse;
The ATTACH statement with the ducklake: prefix instantiates our data lakehouse.
Using the Data Lakehouse
Loading data into the bucket can be done via simple CREATE TABLE statements. The source files can be local or remote.
CREATE TABLE nl_train_stations AS FROM 'https://blobs.duckdb.org/nl_stations.csv';
CREATE TABLE yellow_tripdata_2025_01 AS
FROM 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2025-01.parquet';
Or you can have a single yellow_tripdata table and append to it:
CREATE TABLE yellow_tripdata AS
FROM 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2025-01.parquet';
INSERT INTO yellow_tripdata BY NAME (
FROM 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2025-02.parquet');
Regardless of the format of the source data, the data in the lakehouse is stored in Parquet format. Your bucket contents will look something like this.
Let’s run an aggregation query on our data:
SELECT round(sum(total_amount)), sum(trip_distance), sum(passenger_count)
FROM nyc_tlc.yellow_tripdata
WHERE tpep_pickup_datetime BETWEEN '2025-01-01' AND '2025-01-07';
┌──────────────────────────┬────────────────────┬──────────────────────┐
│ round(sum(total_amount)) │ sum(trip_distance) │ sum(passenger_count) │
│ double │ double │ int128 │
├──────────────────────────┼────────────────────┼──────────────────────┤
│ 14021957.0 │ 2413440.92 │ 700915 │
└──────────────────────────┴────────────────────┴──────────────────────┘
Note that the table metadata is in the Neon PostgreSQL server and the data is in Google Cloud Parquet files.
DuckDB also comes with a handy UI extension where you can explore both the data and the metadata of your lakehouse.
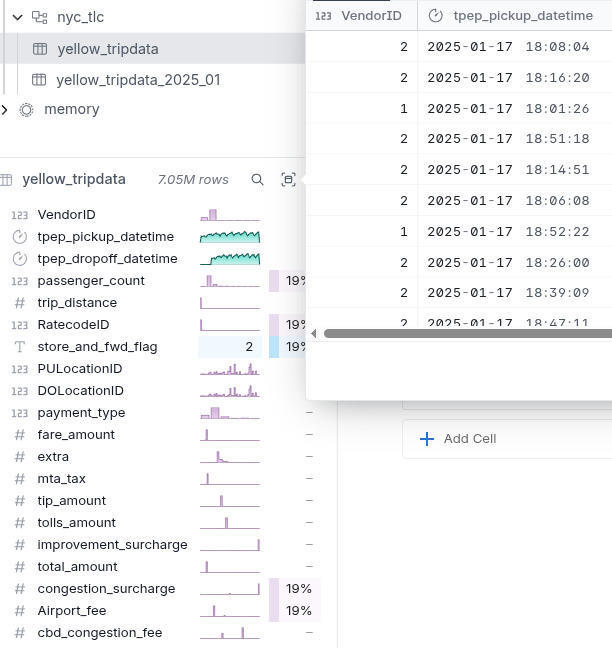
DuckLake supports time travel and querying a previous version of the table can be done using the AT operator:
SELECT COUNT(*) FROM nyc_tlc.yellow_tripdata;
┌────────────────┐
│ count_star() │
│ int64 │
├────────────────┤
│ 7052769 │
│ (7.05 million) │
└────────────────┘
SELECT COUNT(*) FROM nyc_tlc.yellow_tripdata AT (VERSION => 11);
┌────────────────┐
│ count_star() │
│ int64 │
├────────────────┤
│ 3475226 │
│ (3.48 million) │
└────────────────┘
To identify the version of interest, use the ducklake_snapshots function:
FROM ducklake_snapshots('lakehouse');
Conclusion 🎉
You’ve just set up a powerful and flexible lakehouse! This architecture allows you to:
- Store vast amounts of data affordably in cloud object storage.
- Leverage DuckDB’s high-performance analytical engine for querying and transformations directly on your raw data.
- Maintain a robust and centralized metadata catalog using PostgreSQL.
- Decouple compute and storage, scaling them independently.
This DuckDB + Cloud Storage + PostgreSQL (Neon) stack offers a compelling solution for modern data challenges.