In the rapidly evolving world of Large Language Models (LLMs), the ability to run these powerful tools locally on your hardware is likely appealing. Running AI locally grants you unparalleled control, endless customization, and complete data privacy. This guide will walk you through building your personal AI playground, assembling an open-source stack from the model server to a feature-rich user interface and Integrated Development Environment (IDE) support.
Ollama: Your Local LLM Workhorse
At the core of our local LLM stack is Ollama, a powerful and easy-to-use tool for managing and running LLMs. On a Linux environment, you can use the provided one-line script to install Ollama, which will set up the dependencies and GPU drivers. Alternatively, you can follow the manual installation instructions. At its core, the Ollama installation is as simple as unzipping the provided archive. The more challenging part is ensuring it uses the available GPU, a process that is highly dependent on the operating system, GPU model, and driver availability.
Running Ollama
Once installed, start the Ollama server via ollama serve. The most critical step is ensuring it uses your available GPU. If detected correctly, you should see log output referencing your GPU:
> ollama serve
source=gpu.go:217 msg="looking for compatible GPUs"
source=types.go:130 msg="inference compute" id=GPU-9ee00d0c-6562-af57-fa91-f023dae63b1e library=cuda variant=v12 compute=7.5 driver=12.9 name="NVIDIA T1200 Laptop GPU" total="3.6 GiB" available="3.6 GiB"
You can think of the Ollama server as a service similar to Docker. Once started, you can download and run models similar to Docker images. To download and start interacting with a model, use:
> ollama run phi3
>>> Send a message (/? for help)
This will download the Phi-3 model and start a chat session. The ollama serve command runs the server that downloads and loads the model, while the ollama run command starts a client that allows you to interact with it.
You can use various ollama commands to manage the images:
> ollama list
NAME ID SIZE MODIFIED
deepseek-r1:1.5b e0979632db5a 1.1 GB 10 hours ago
phi3:latest 4f2222927938 2.2 GB 23 hours ago
gemma3:latest a2af6cc3eb7f 3.3 GB 23 hours ago
> ollama rm deepseek-r1:7b
GPU vs. CPU: A Tale of Two Speeds
The performance of your local LLM is heavily dependent on your hardware.
- With a GPU: If you have a GPU, such as one from NVIDIA, Ollama will automatically leverage it to run the models. This results in a significant performance boost, making the model’s response time fast and interactive.
- Without a GPU: If a GPU is not available, Ollama will fall back to using the CPU. While functional, the response times will be noticeably slower, making it less practical for real-time interaction.
- Hybrid Approach: If a model is too large to fit entirely into your GPU’s VRAM, Ollama is smart enough to split the load between the GPU and your system’s memory. This allows you to run larger models than your GPU could handle alone, albeit with a performance trade-off.
The nvidia-smi command will give you an idea if your NVIDIA GPU card is configured correctly.
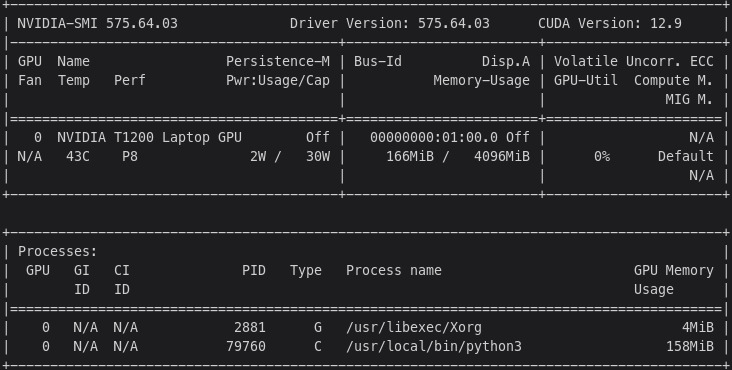
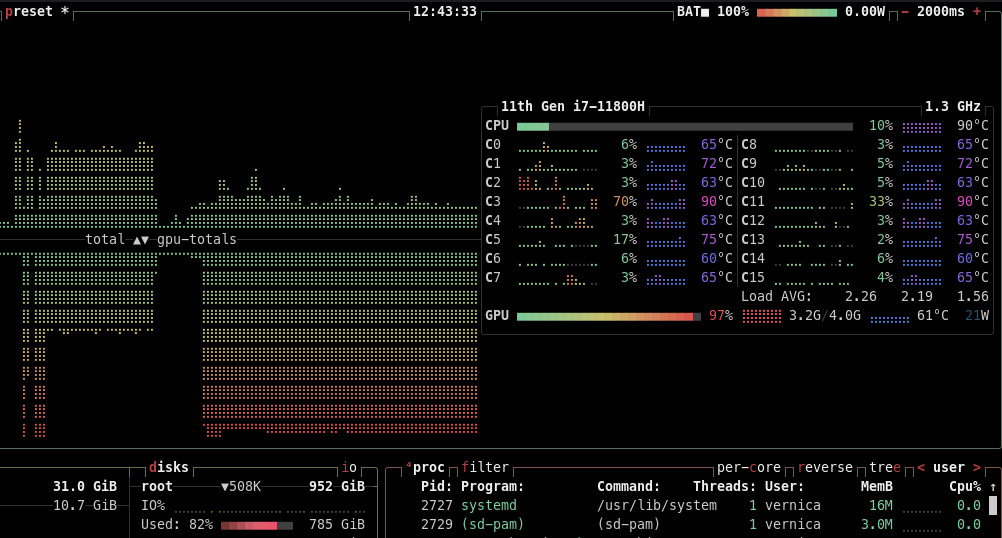
Moreover, the btop tool is very valuable in monitoring the GPU vs CPU usage when running the inference. Notice the heavy GPU usage and the light CPU usage in the screenshot below.
Finally, the ollama ps command will tell you which models are loaded and how they are utilizing the hardware (CPU or GPU):
> ollama ps
NAME ID SIZE PROCESSOR UNTIL
phi3:latest 4f2222927938 6.5 GB 42%/58% CPU/GPU 4 minutes from now
Pay attention to the model sizes in relation to your available memory. Start small and work your way up.
Open WebUI: A Rich Interface for Your LLMs
While the command line is great for quick interactions, a dedicated web interface provides a much richer user experience. This is where Open WebUI comes in.
Deploying Open WebUI is a breeze with Docker. A simple docker run command is all it takes to get a beautiful and powerful UI for your local LLMs. The GPU can be made available to the Docker container and will be leveraged for more advanced features such as voice support and Retrieval-Augmented Generation (RAG).
Features Galore
Open WebUI is packed with features that enhance your interaction with LLMs, including:
- Chat History: Keep track of your conversations and revisit them later.
- Model Management: Easily switch between different models you have downloaded with Ollama.
- RAG: This powerful feature allows your LLM to access external knowledge sources, such as your documents. By providing relevant context, RAG enables your models to answer questions about specific data with high accuracy.
- Voice Support: Bring your conversations to life via voice input and output.
Many of the features can be configured via the rich admin UI.
In order for the containerized Open WebUI to reach the Ollama server running on your host machine, Ollama needs to listen to all network interfaces, not just localhost. You can achieve this by starting the server with: OLLAMA_HOST=0.0.0.0 ollama serve.
Continue: Supercharge Your Coding with Local LLMs
For developers, the ability to integrate LLMs directly into their IDE is a game-changer. Continue is an open-source VSCode extension that brings the power of your local Ollama server to your coding workflow.
With Continue, you can:
- Get Code Suggestions: Receive intelligent code completions as you type.
- Refactor Code: Ask your local LLM to refactor a block of code for better readability or performance.
- Explain Code: Highlight a piece of code and get a clear explanation of what it does.
- Generate Unit Tests: Automatically generate unit tests for your functions.
Continue allows you to select a Local Assistant setup (no login required), and it can connect to your Ollama server and detect the available models.
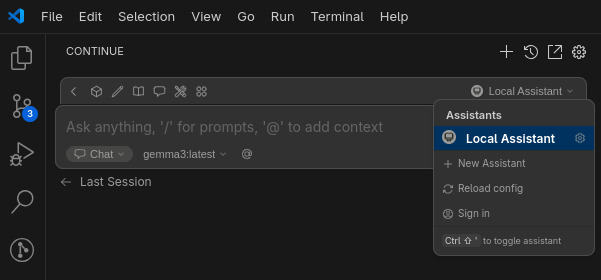
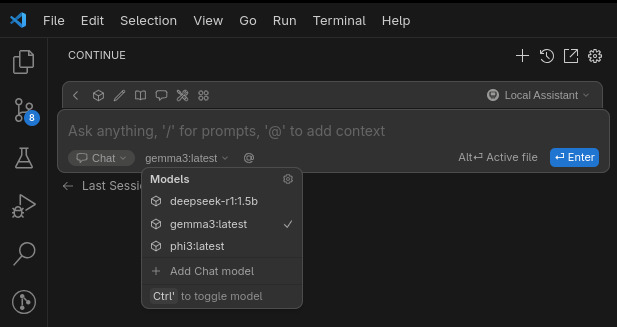
For Continue to be effective, especially for tasks like explaining or refactoring large blocks of code, you should increase Ollama’s context window. This allows the model to consider more of your code at once. Start the server with a larger context length like so: OLLAMA_CONTEXT_LENGTH=8192 ollama serve.
Side Note: WebLLM Chat - Local LLMs in Your Browser
As a final note, it’s worth mentioning the WebLLM Chat application. This innovative project allows you to run open-source models directly within your Chrome browser.
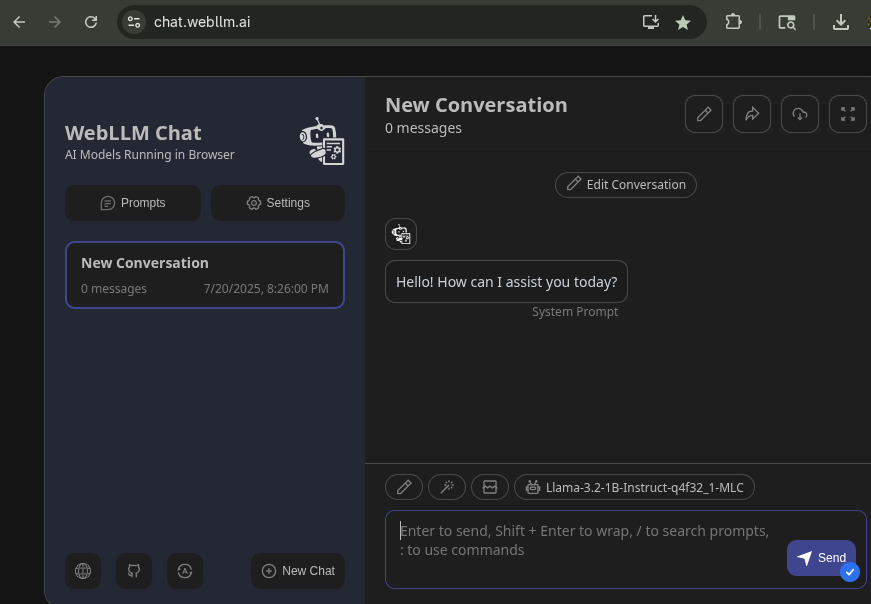
Once the first prompt is provided, the application will download the selected model locally and run the inference in your browser. By leveraging the WebGPU feature, WebLLM Chat can tap into your local GPU for accelerated inference, all without needing to install any software. This is a fantastic demonstration of the power and flexibility of modern web technologies.
Conclusion
Setting up a personal, high-performance LLM stack on your own hardware is more accessible than ever. We’ve walked through a powerful, open-source toolkit that puts you in control:
- Ollama provides the engine for running models efficiently.
- Open WebUI delivers a polished, feature-rich interface for interaction.
- Continue seamlessly integrates AI capabilities directly into your coding workflow.
These tools form the building blocks of a robust local AI ecosystem, offering a sandbox for experimentation, development, and learning — all on your machine. The world of open-source AI is evolving at a breakneck pace, and with this setup, you are perfectly positioned to explore it. What cool projects would you build with a local LLM stack?