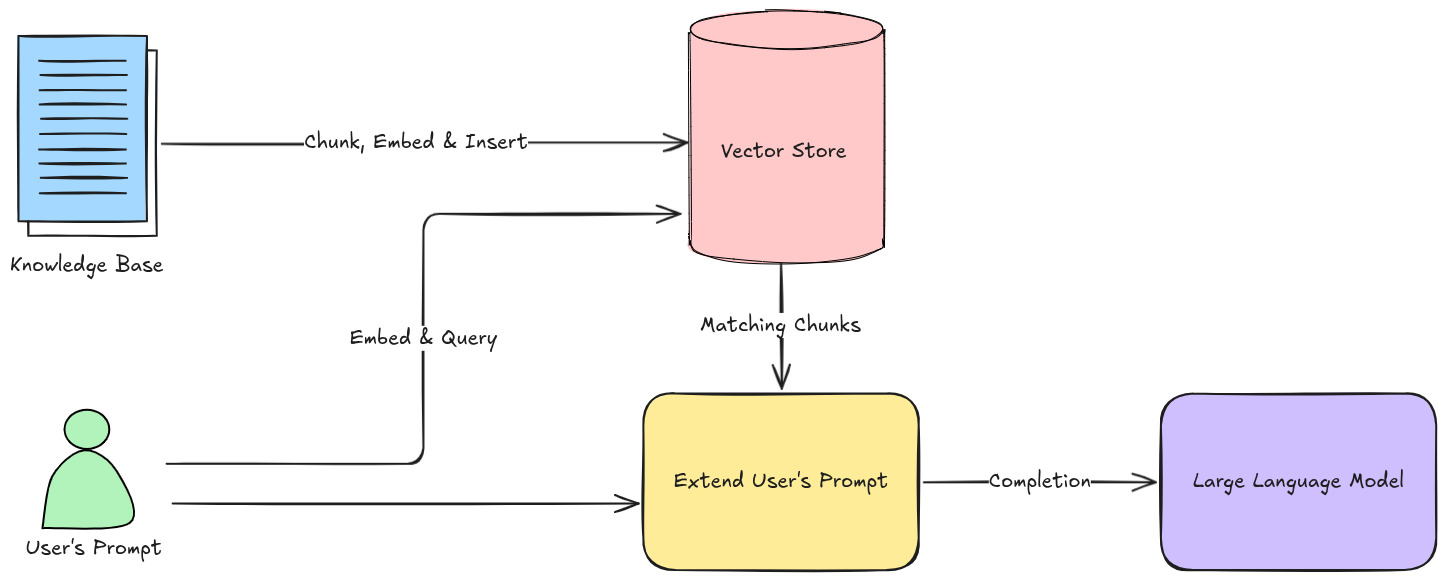
Retrieval Augmented Generation (RAG) has revolutionized how Large Language Models (LLMs) access and utilize external knowledge, moving beyond static training data to deliver more accurate, relevant, and up-to-date responses. While basic RAG setups are powerful, achieving peak performance and addressing complex real-world scenarios often requires a more sophisticated approach. This post explores advanced RAG techniques that go beyond the fundamentals, empowering developers to build more robust and intelligent LLM applications.
The Paramount Role of Context
At the heart of every effective RAG system lies context. The quality, relevance, and sufficiency of the context provided to the LLM directly determine the quality of its generated response. Insufficient or irrelevant context can lead to hallucinations, inaccurate information, or a complete failure to respond. Advanced RAG techniques primarily focus on meticulously enhancing this context throughout the entire RAG pipeline.
Phase 1: Pre-Retrieval (Preparing the Foundation) 🧱
The journey to superior RAG begins before the first search query is made. How we chunk and structure our data is critical. Moving beyond simple, fixed-size chunks can dramatically improve retrieval quality.
- Parent-Child or Small-to-Big Chunking: This strategy creates smaller, more precise chunks for embedding and searching, while linking them to larger “parent” chunks that contain more context. During retrieval, the system first finds the most relevant small chunk and then retrieves its larger parent document to provide the LLM with richer, more complete context. This method optimizes the trade-off between retrieval precision and contextual richness for generation. Small, focused chunks are better for vector similarity search, while the LLM needs the broader context from the parent chunk to synthesize a good answer. Perform Parent Document Retrieval with MongoDB and LangChain
- Hierarchical Indexing: For very large documents, we can create a hierarchical structure. Start by summarizing each document or section, embed these summaries, and create a top-level index. The system first searches the summary index to identify the most relevant documents, then performs a more granular search within the chunks of only those selected documents. LlamaIndex | Document Summary Index
- Metadata Filtering: Beyond the text itself, attaching metadata (like dates, authors, topics, or product IDs) to each chunk creates powerful filtering capabilities. We can use an LLM or an entity extraction model to automatically identify these entities from the user query and pre-filter the knowledge base before performing a vector search. This ensures we only search within the most relevant subset of our data.
- Graph RAG: Leveraging Relationships: While vector search excels at finding semantic similarity, it can miss explicit relationships. By storing information in a Knowledge Graph, we can answer queries that rely on connections. For example, to answer “Which engineers worked on the ‘Phoenix’ project and are based in the London office?”, a graph query can traverse the relationships between “engineers,” “projects,” and “locations” with precision that is often difficult for vector search alone. This involves converting unstructured text into structured graph nodes and edges during the indexing phase. GraphRAG with MongoDB and LangChain
Phase 2: Retrieval (Understanding User Intent) 🔎
User queries are often imperfect—they can be vague, overly complex, or use different terminology than our documents. Query transformation techniques refine the user’s input for better retrieval results.
- Query Routing: Before retrieving any data, a Query Router can analyze the user’s intent. For instance, a query like “What were our sales in Q2?” could be routed to a Text-to-SQL tool to query a sales database. A query like “Summarize the new HR policy” would be routed to the traditional vector search over the HR document knowledge base. This ensures the right tool is used for the job, greatly expanding the capabilities of our application. LlamaIndex | Router Query Engine
- Query Rewriting & Expansion: This technique involves using an LLM to rephrase a user’s query to be more detailed and clear. For example, the brief query “AI latest” could be expanded to “Recent advancements in artificial intelligence technology.” This helps bridge the semantic gap between the user’s language and the document’s content. LangChain | RePhraseQuery
- Query Decomposition: Complex questions that require multiple steps of reasoning can be broken down. A query like “Compare the health benefits of green tea and black tea” can be decomposed by an LLM into two separate queries: “What are the health benefits of drinking green tea?” and “What are the health benefits of drinking black tea?” The system then retrieves information for both, combining the retrieved context to form a comprehensive answer. LlamaIndex | Sub Question Query Engine
- Hypothetical Document Embeddings (HyDE): This technique addresses the challenge of semantic misalignment: user queries are questions while documents are statements. Instead of embedding the user’s query directly, an LLM first generates a hypothetical document or answer that is likely to be relevant to the query. This generated document, which is rich in keywords and context, is then embedded and used to search the vector database, often leading to more relevant results. LangChain | HyDE Retriever
- Fusion Retrieval / Hybrid Search: Relying solely on vector search can sometimes miss exact keywords or acronyms. Hybrid search combines the strengths of both keyword-based search (like the robust BM25 algorithm) and semantic vector search. The system retrieves results from both methods and fuses them into a single, comprehensive set using an algorithm like Reciprocal Rank Fusion (RRF). RRF is effective because it prioritizes documents that rank highly in both search methods, without requiring normalization of the disparate scores from each. LlamaIndex | Reciprocal Rerank Fusion Retriever
Phase 3: Post-Retrieval (Refining and Focusing the Context) ✨
After retrieving a set of potentially relevant documents, it’s crucial to refine and organize this context before sending it to the LLM. This final stage ensures the model receives only the highest quality, most relevant information.
- Re-ranking for Precision: The initial retrieval process is optimized for speed and recall. We use a re-ranking step to improve precision by sorting the most relevant documents to the top. This is often done with a more powerful, but slower, model known as a Cross-Encoder, which re-evaluates the top K documents from the initial search. Unlike a bi-encoder, a cross-encoder evaluates a
(query, document)pair together, allowing the model to analyze the nuanced interaction between the query and the document, generating a much more accurate relevance score. - Context Selection & Compression: Context compression techniques address the finite context window of LLMs and the “lost in the middle” problem. These techniques refine the retrieved information before passing it to the main LLM. Methods like LLMLingua use a smaller, more efficient LLM to analyze and compress the context by removing less important words or sentences. This creates a shorter, more concise input for the main LLM, reducing noise and improving its ability to focus on the most critical information to answer the query.
Phase 4: Evaluation (Measuring What Matters) 🧪
Building an advanced RAG pipeline is an iterative process, and we can’t improve what we can’t measure. A robust evaluation framework is essential for quantifying the impact of each component, from our chunking strategy to our re-ranker. A comprehensive approach involves assessing the two core parts of the RAG pipeline: retrieval and generation.
- Retrieval: Key indicators include classic information retrieval metrics like Hit Rate (did the correct document appear in your retrieved set?) and Mean Reciprocal Rank (MRR) (how high up the list was the correct document?). LlamaIndex | Retrieval Evaluation
- Generation: Modern frameworks like Ragas or ARES leverage LLMs to score the quality of the final output across several crucial dimensions. These include Faithfulness, which measures if the generated answer is grounded in the provided context to prevent hallucinations; Answer Relevancy, which checks if the answer directly addresses the user’s query; and Context Precision, which evaluates whether the retrieved context was concise and relevant. By systematically tracking these metrics, we can confidently iterate and prove that our advanced techniques are delivering real improvements.
Conclusion: Building a Modular RAG Framework
Advanced RAG is not a single technique but a modular framework of interchangeable components. By understanding the different strategies available at each stage of the pipeline—from sophisticated indexing and query transformations to hybrid search, re-ranking, and context compression—we can mix and match components to build a RAG system tailored to our specific needs. This modular approach allows for continuous experimentation and improvement, enabling us to construct truly state-of-the-art LLM applications.